Physics-Informed Machine Learning for Efficient Sim-to-Real Data Augmentation in Micro-Object Pose Estimation
Abstract
Accurate pose estimation is crucial for controlling optical microrobots in high-precision tasks such as object tracking and autonomous biological studies. However, collecting and labeling large-scale microscopy datasets is costly and time-consuming.
To address this, we introduce a physics-informed deep generative framework that leverages wave optics and depth-aware rendering within a GAN-based architecture. Unlike traditional AI-only approaches, our method realistically simulates complex microscopy effects—like diffraction and depth-dependent imaging—enabling the efficient generation of synthetic training data.
Our approach achieves:
- 35.6% improvement in image realism (SSIM)
- Real-time rendering speeds (0.022s/frame)
- Pose estimation accuracy of 93.9% (pitch) and 91.9% (roll), closely matching real-data-trained models
This framework not only enhances data efficiency but also generalizes to unseen microrobot poses, enabling scalable and robust training without additional real-world data.
Method

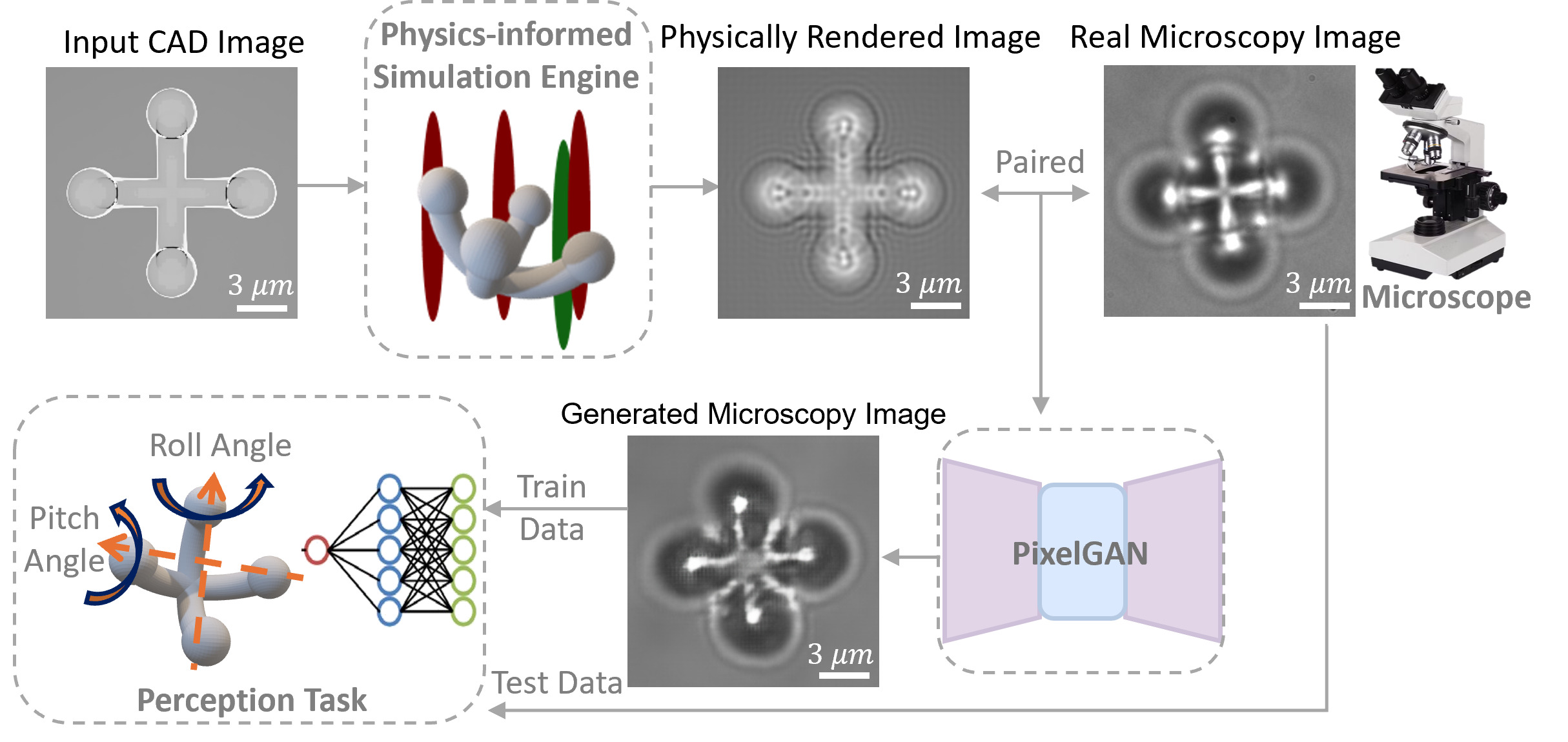
Pipeline
The pipeline starts by building a virtual optical system using NVIDIA’s Isaac Sim, incorporating real-time optical parameters and simulated microrobot poses. A virtual camera captures initial CAD images and depth maps aligned with real experimental setups. Foreground segmentation via k-means clustering enables tight cropping around the microrobot, reducing computation.
Next, a wave optics-based image formation process is used:
- The microscope’s optical transfer function (OTF) is computed.
- The scene is depth-discretized along the z-axis and transformed into the frequency domain for efficient OTF-based convolution.
- A numerical aperture (NA) cutoff filters out non-physical frequencies, ensuring realistic optical simulation.
- Parseval’s theorem is applied to preserve energy and signal fidelity.
Finally, a PixelGAN-based sim-to-real module refines the rendered images, reducing the visual gap between simulation and real microscope data.
Experiments
Datasets and Implementation Details:
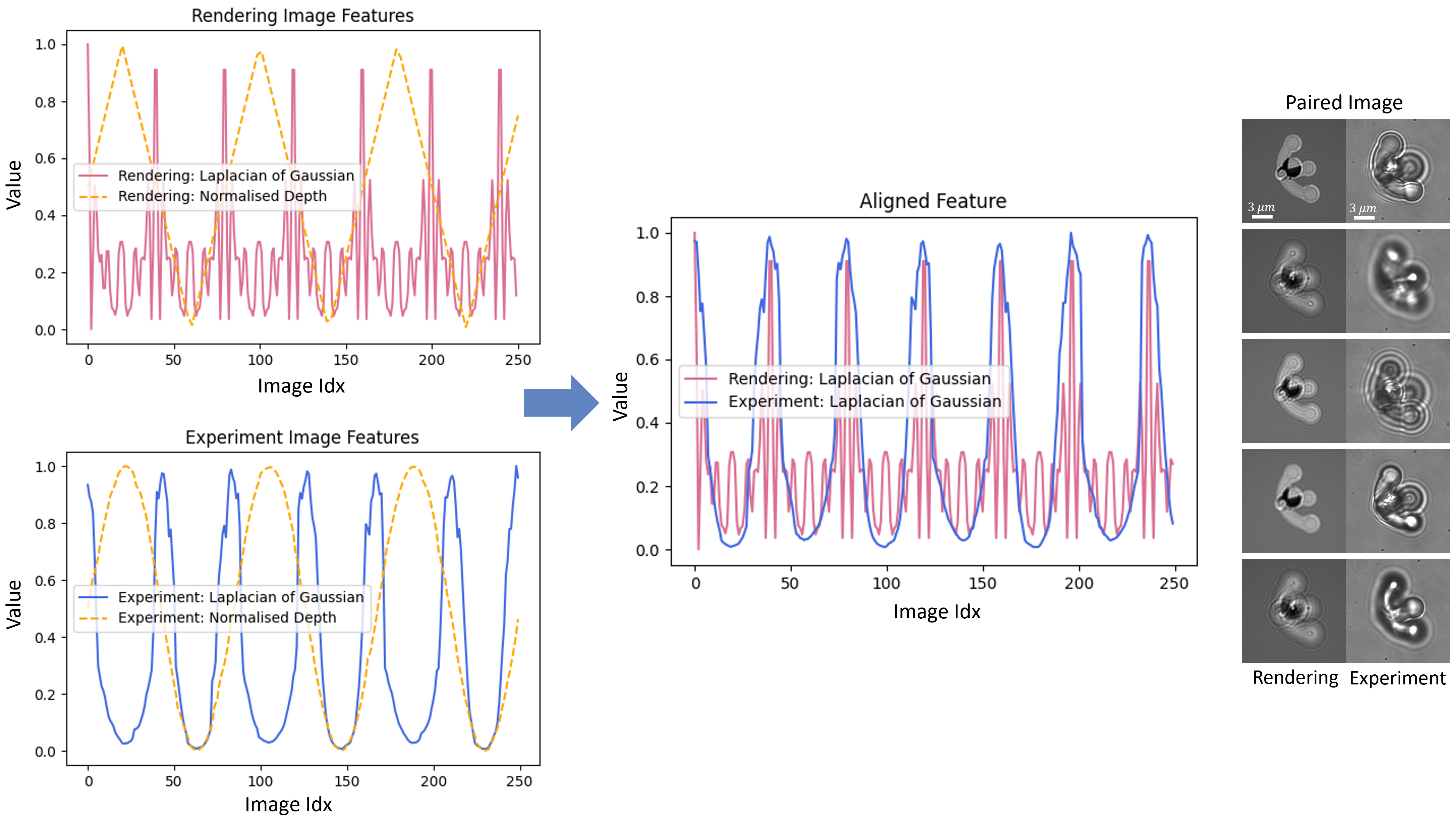
The aligned data used for PixelGAN training consists of 15,820 images (each consisting of one physically rendered image and one experiment image), corresponding to 35 sets of optical microrobots with different poses. The resulting paired data are shown in the right part of Fig. 3, each pair has one rendered image and one experimental image on the same depth. Of these, 70% were allocated to the training set, 15% to the validation set, and 15% to the test set. The model is trained for 100 epochs.
The code was implemented in PyTorch 1.8.1 and Python 3.8, running on a system equipped with 1 NVIDIA A100 GPU with 80 GB of memory. The CUDA version used was 11.4, and the inference precision was set to float32.
Code
Will be released after the paper is accepted.
Results
Image Generation Results


We evaluated three methods for generating microrobot images:
- GAN-only (using CAD images)
- Physics-based rendering
- Hybrid: Rendering + GAN
Our hybrid approach—combining physics-based rendering with a GAN—achieved the best image quality, improving SSIM by 35.6% over GAN-only methods, while maintaining fast rendering speeds (0.022s per image), as shown in Table 1.
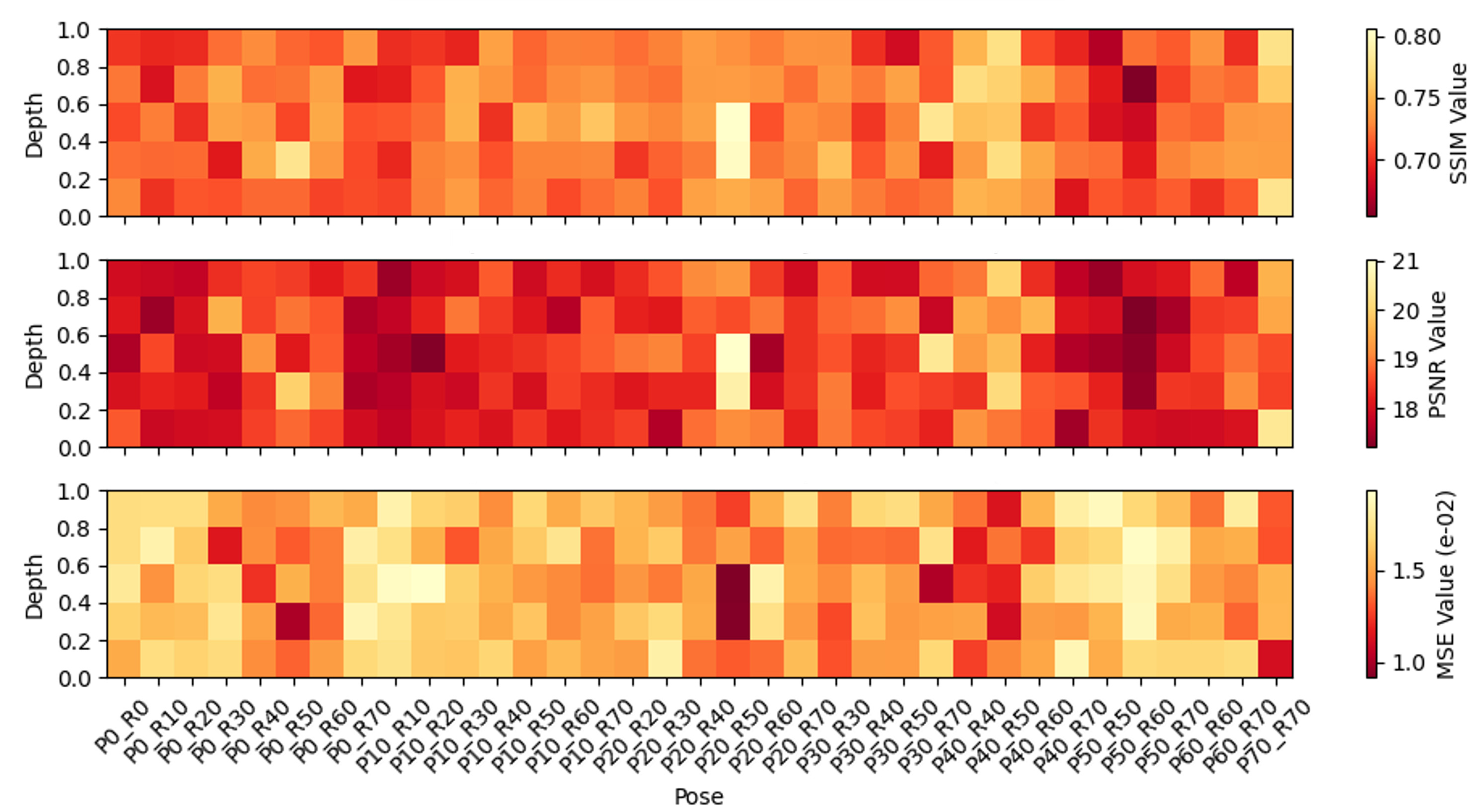
Example outputs in Fig.4 and pose-wise performance heatmaps in Fig.5 demonstrate that the hybrid method consistently outperforms others across all 35 pose classes, producing the most realistic and accurate synthetic images.
Pose Estimation Results
To assess the value of our synthetic data, we tested pose estimation (pitch and roll) using three model backbones:
- CNN and ResNet18 (convolution-based, strong local feature extraction)
- ViT (transformer-based, captures global dependencies)
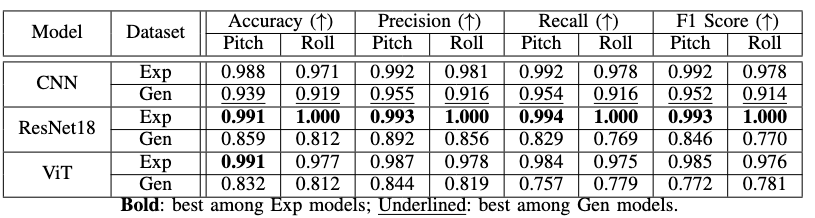
All models were trained for 30 epochs and evaluated on 350 real test images covering 35 poses (strictly excluded from training to avoid data leakage). Result is in Table 2.
Findings:
- Models trained on synthetic data performed slightly lower than real-data models (accuracy gap: 5–18%).
- The best CNN model showed only a 5.0% (pitch) / 5.4% (roll) drop in accuracy.
- Precision, recall, and F1 score decreased modestly (3.7–4.0% for pitch, 6.2–6.6% for roll).
These results demonstrate that our synthetic dataset closely matches real data quality, enabling robust microrobot pose estimation with minimal accuracy loss.
Hybrid Dataset Evaluation
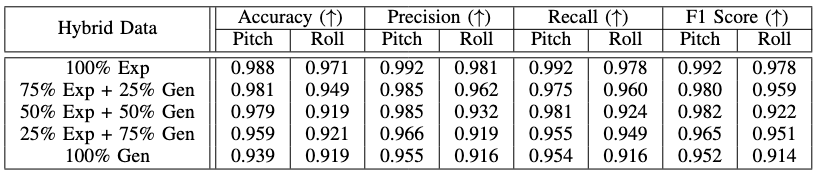
We tested how mixing real experimental images with our generated images impacts pose estimation (CNN backbone). Training datasets were built with varying ratios of real-to-generated data (100% Exp, 75/25, 50/50, 25/75, 100% Gen) and evaluated on the same 350 real test images (excluded from training to prevent leakage).
Results:
- Accuracy gradually decreases as the proportion of generated data increases.
- Compared to 100% real data:
- Pitch accuracy drops only 0.7–5.0%
- Roll accuracy drops 2.3–5.4%
- Key finding: Mixing 50% generated data causes only a 0.9% drop in pitch accuracy, while roll accuracy at 100% generated data matches the 50% case.
These results show that moderate integration of generated images preserves performance, confirming the effectiveness of our synthetic data for training pose estimators.
Generalisability to Unseen Poses

To test whether our model can handle unseen microrobot poses, we split the dataset into:
- Set A (5 challenging poses): hard to reach in physical experiments, asymmetric, and prone to strong optical artifacts
- Set B (30 remaining poses)
We trained two models:
- PixelGAN-35 (trained on all poses: Set A + B)
- PixelGAN-30 (trained only on Set B, with Set A unseen)
Results:
- Set A is consistently harder, with 5.3–5.5% lower accuracy than Set B.
- On unseen poses (Set A), PixelGAN-30 showed only a 2.5% accuracy drop compared to PixelGAN-35 (0.866 vs 0.888), confirming strong generalisability.
- On seen poses (Set B), the difference was also small (2.4% accuracy drop).
- Precision, recall, and F1 followed the same trend, with modest relative drops.
These findings demonstrate that our model generalises well to unseen, hard-to-simulate poses, maintaining robust performance even without direct training examples.